
![]()
![]()
|
|
| Real-Time and Realistic 3D Facial Expression Cloning | |
| Jung-Bae Kim, Youngkyoo Hwang, Won-Chul Bang and James D.K. Kim (Samsung Electronics, Korea) | |
| The Sixth TRIZ Symposium in Japan, Held by Japan TRIZ Society on Sept. 9-11, 2010 at Kanagawa Institute of Technology, Atsugi, Kanagawa, Japan | |
| Introduction by Toru Nakagawa (Osaka Gakuin Univ.), Mar. 21, 2011 | |
| [Posted on Sept 19, 2011] |
For going back to Japanese pages, press ![]() buttons.
buttons.
Editor's Note (Toru Nakagawa, Sept. 18, 2011)
This paper was presented by Jung-Bae Kim a year ago in an Poster session at the Sixth TRIZ Symposium in Japan, 2010
. Presentation slides have been posted in PDF both in English and in Japanese translation (by Osamu Ikeda) in the Members-only page of Japan TRIZ Society's Official Site since last March. For wider circulation, they are now posted here publicly under the permissions of the Authors.


Last March I posted an introduction to this paper as a part of my Personal Report of the Symposium
Two known methods, i.e., Motion-capture and Vision-based methods, were used as the bases for Feature Transfer. Separation of two types of parameters, i.e., those dependent on individuals but time independent from those variable with time, is the key to the solution. This is an excellent case study of problem solving in IT/software field.
| Top of this page | Abstract | Slides in PDF |
Slides in Japanese, PDF |
Nakagawa's Introduction | Nakagawa's Personal Report of Japan TRIZ Symp. 2010 |
Japan TRIZ Symp. 2010 |
Japanese page |
[1] Abstract
Real-Time and Realistic 3D Facial Expression Cloning
Jung-Bae Kim, Youngkyoo Hwang, Won-Chul Bang and James D.K. Kim
(Samsung Electronics, Korea)Abstract
3D virtual world has been researched intensively. In particular, animating facial expression of an avatar, representative for a user, has been issued. There are two kinds of interface to clone the user's facial expression: mocap-based interface using lots of IR cameras and markers, and vision-based interface using only one color camera. The vision-based interface would be desirable for most users at home. However this interface has very challenging problems to capture and track the user's subtle 3D expression in real time. We present a novel method to deal with those difficulties by using TRIZ methodology. We use a personalized 3D expression model to do real-time cloning, and make a muscle model to track 3D movements on cheeks and forehead having no outstanding features.
Extended Abstract
In 3D virtual world, when a virtual avatar mimics the user’s facial movement, it gives him not only interest but also immersion that he enters and lives himself in virtual world. There are two representative methods in this technology. One is based on the motion capture device called mocap-based system; the other is based on just one camera, called vision-based system.
The mocap-based system attaches almost one hundred markers on the user’s face and uses more than seven well-calibrated IR cameras. It can tracks subtle 3D expression, however, it also needs post-processing to reduce internal noise. So, it is not easy for general users because of several problems: not real-time processing, very huge system, cumbersome markers, expensive device, etc.
The vision-based system would be desirable for most users at home since a camera device is cheap and easy to use: no markers on face, and simple to set up. Unfortunately, vision-based system has very challenging problems to capture a user’s 3D expression using monocular camera, and to track subtle facial movement without marker.
In this paper, using TRIZ methodology, we propose a novel vision-based expression cloning system having two major features: 1) cloning 3D facial expression in real time and 2) cloning a subtle movement on cheek and forehead.
Since 3D expression cloning requires much computational burden, a traditional vision-based 2D expression cloning system can’t process it in real time. We applied the separation in time principle of TRIZ on this problem. In initial phase, the system performs the personalized shape fitting in order only to discover the user’s facial appearance. After that, the system tracks head motion and expression change. As the result, it is possible to clone 3D facial expression in real time.
Meanwhile, in order to have mocap system-level accuracy, we need more than 60 expression control points. By applying the separation in condition principle of TRIZ on this problem, we divide these points into two groups: one is able to be tracked with a camera, the other is not. The latter, the points on forehead and cheek, can be tracked only with mocap system.
By applying the invention principle and smart little creature modeling of TRIZ, this kind of points are not tracked but be generated by themselves and move organically with neighbor points. This idea is that a muscle model learns the motion of the mocap DB and generates movement of the expression control points. Finally, we can clone facial expression with high accuracy as the level of the mocap method.
The experimental system is shown in Fig. 1. Even thought it uses only 1 color camera, it achieves real-time, convenience and high accuracy together.

Fig.1. Proposed vision-based 3D facial expression cloning system
[2] Presentation Slides in PDF
Presentation Slides in English in PDF
Presentation Slides in Japanese in PDF
[3] Introduction to the Presentation (by Nakagawa)
Excerpt from:
Personal Report of The Sixth TRIZ Symposium in Japan, 2010, Part D
by Toru Nakagawa (Osaka Gakuin University),
Posted on Mar. 21, 2011 in "TRIZ Home Page in Japan"
Jung-Bae Kim, Youngkyoo Hwang, Won-Chul Bang and James D.K. Kim (Samsung Electronics, Korea) [E13, P-A6] gave a Poster presentation with the title of "Real-Time and Realistic 3D Facial Expression Cloning". This is another nice case study presented by Korean industry. The Authors' Abstract is quoted here first:
3D virtual world has been researched intensively. In particular, animating facial expression of an avatar, representative for a user, has been issued. There are two kinds of interface to clone the user's facial expression: mocap-based interface using lots of IR cameras and markers, and vision-based interface using only one color camera. The vision-based interface would be desirable for most users at home. However this interface has very challenging problems to capture and track the user's subtle 3D expression in real time. We present a novel method to deal with those difficulties by using TRIZ methodology. We use a personalized 3D expression model to do real-time cloning, and make a muscle model to track 3D movements on cheeks and forehead having no outstanding features.
The Authors show their task for their research in the slide (below-left). They are working for the development of realistic 3D Mixed Reality (MR) software. Mixed Reality is the world where user's Real World can be projected smoothly onto the Virtual Reality (VR) World. They show possible applications, e.g., Virtual sports, Virtual entertainment, Virtual commerce, etc. For such applications, the Authors want to build a method for cloning (or imitating) user's natural face expressions to his/her avatar's, as shown in the bottom part of the slide (below-left). For such a purpose, two methods were known (slide (below-right)). First method is used for movie CG, by attaching a large number of markers on the face, using ten or so cameras, and spending days for accurately capturing and transferring the face expressions. Second method is used for real-time teleconferencing, by using just one camera and no markers on the face, where low accuracy is accepted.

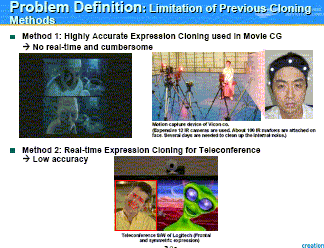
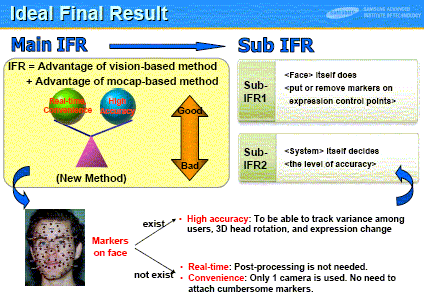
The goal of the Authors' study is to develop a new method overcoming the limitations of the previous methods. The Motion Capture (Mocap)-based method (Method 1) has high accuracy but lacks convenience and real-time feature, whereas the Vision-based method (Method 2) is convenient and real-time but lacks high accuracy. The Ideal Final Result is to achieve high accuracy, convenience, and real-time nature, the Authors say (slide (right)). They reconsider the roles of the markers on face. With the markers, the software tracks the variance among users, 3D head rotation, and expression change, in an accurate manner. However, they become obstacles in achieving convenience and real-time processing. |
 |
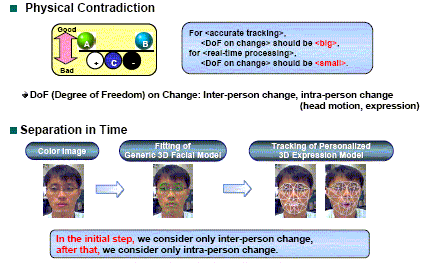
Now the Authors formulated the problem with TRIZ and generated ideas for the solution. For accurate tracking of expression, the software should be able to accept big change in the face expression, whereas for real-time processing it should accept only small change. The Authors notice there are two types of changes (or differences): one is the inter-person change (i.e., differences by person), and the other intra-person change (i.e., head motion and face expression change of a person). Thus they divided the software processing into two steps (or time periods). In the initial step, a user's image is processed to fit to general 3D facial model for adjusting to the person; and after that the user's face expression is to be tracked real time by considering the intra-person change. |
 |
The next problem was related to the role of the markers. The markers should exist, and they should not exist. The Authors noticed that among the expression control points, where markers are usually placed, some are track-able by using ordinary vision method. They include eyes, nose, lips, ears, bottom of chin, etc. Since they are clearly locatable in the vision image, they do not need markers to be attached. However, there are some other expression control points which can only be located with the markers in the Motion-Capture method. They include middle places in forehead, cheeks, etc. Since they are flat parts, their exact position cannot be located well. Anyway the distinguishment of these two types of control points gives an important key. |
 |
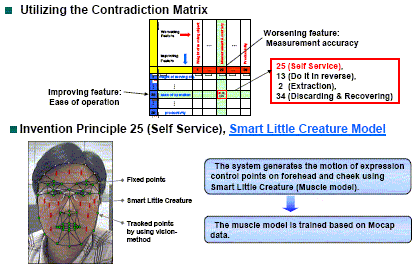
Thus the next problem was how to locate the control points in the middle of forehead, cheeks, etc. The Authors used the Contradiction Matrix and found the Invention Principle 25 'Self Service' as the recommendation. So they applied the Smart Little People (SLP) modelling method. The Authors set up a spatial network of the control points, belonging to the two types together, and assumed smooth change in their displacements which are calibrated by the locations of track-able points. [*** They named this 'Muscle Model', but actually have not used any model of physical muscle structure.] The smooth changes in the Muscle Model software are trained on the basis of Motion-Capture data, the Authors say. |
 |
On the basis of the ideas so far obtained, the Authors built up the solutions as follows. The first part of the solution is the tracking of Feature Points (slide (right)). A color image of the user (a) is processed to build up a Generic 3D Facial Model of the user (b) by using the databases of generic 2D multi-view and 3D Facial records. Then the model (b) is used for tracking the Feature Points (c) of the user's face expression in real time. [*** At the bottom-right part of the slide, they mention about the use of 'Personalized 3D Morphable Expression Model' without any explanation. I wonder if this is obtained by use of the user's expression images of 12 actions, e.g. lifting eyebrow, closing eyes, opening mouth, etc., which are shown in the Authors' experiment slide (omitted here).] |
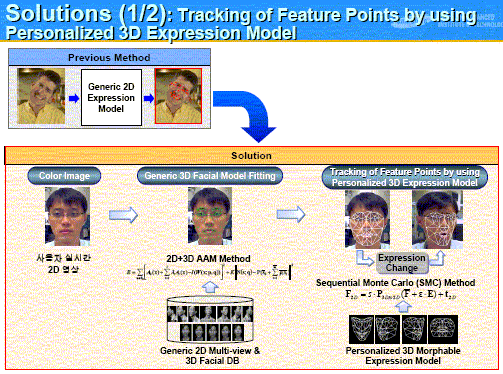 |
Then in the second part of the solution, the positions of the Expression Control Points (d) are generated on the basis of the Feature Points which are tracked in real time. For this generation, they apply the Muscle Model, which has been derived by the processing of the Motion-Capture DB. Then the generated date of Expression Control Points (d) are transferred to those of the Avatar's [probably by using Avatar's personalized 3D facial model], and then are processed by expression rendering to get a cloned expression (e) as shown at the right end of the slide (right). |
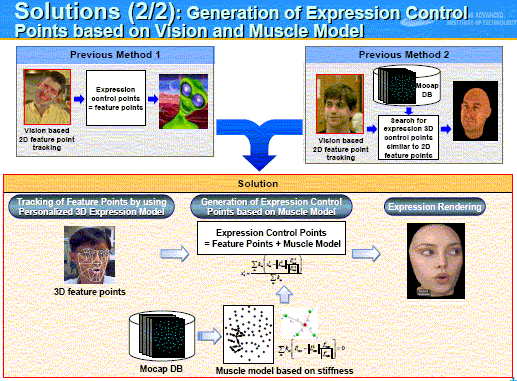 |
In the slide (right), the Authors show the verification of the solution system they developed. At the top of the slide, they summarize the system configuration. At the bottom half, they compare the performance of their solution method with those of the previous methods. The new method uses only one camera, no attached makers on face, and processes 38.3 figures/sec, can track any expression, with head rotation of angle -90 to +90 degrees, using 75 expression control points. [*** I think this is an excellent case study where TRIZ is well applied to a software problem. I wish to post the PDF file of the Authors' presentation slides in this Web site under their kind permission.] |
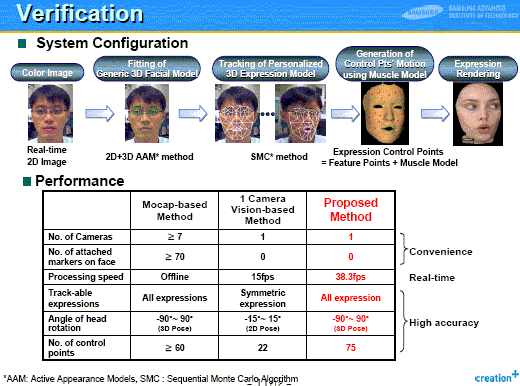 |
[Note: We have now posted the original presentation slides in the present Web site in English
| Top of this page | Abstract | Slides in PDF |
Slides in Japanese, PDF |
Nakagawa's Introduction | Nakagawa's Personal Report of Japan TRIZ Symp. 2010 |
Japan TRIZ Symp. 2010 |
Japanese page |
Last updated on Sept. 19, 2011. Access point: Editor: nakagawa@ogu.ac.jp